
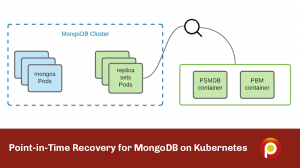
 Running MongoDB in Kubernetes with Percona Operator is not only simple but also by design provides a highly available MongoDB cluster suitable for mission-critical applications. In the latest 1.8.0 version, we add a feature that implements Point-in-time recovery (PITR). It allows users to store Oplog on an external S3 bucket and to perform recovery to a specific date and time once needed. The main value of this approach is a significantly lower Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
Running MongoDB in Kubernetes with Percona Operator is not only simple but also by design provides a highly available MongoDB cluster suitable for mission-critical applications. In the latest 1.8.0 version, we add a feature that implements Point-in-time recovery (PITR). It allows users to store Oplog on an external S3 bucket and to perform recovery to a specific date and time once needed. The main value of this approach is a significantly lower Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
In this blog post, we will look into how we delivered this feature and review some architectural decisions.
Internals
For full backups and PITR features, the Operator relies on Percona Backup for MongoDB (PBM), which by design supports storing operations logs (oplogs) on S3-compatible storage. We run PBM as a sidecar container in replica sets Pods, including Config Server Pods. So each replica set has two containers from the very beginning – Percona Server for MongoDB (PSMDB) and Percona Backup for MongoDB.

While PBM is a great tool, it comes with some limitations that we needed to keep in mind when implementing the PITR feature.
One Bucket
If PITR is enabled, PBM stores backups on S3 storage in a chained mode: Oplogs are stored right after the full backup and require it. PBM stores metadata about the backups in the MongoDB cluster itself and creates a copy on S3 to maintain the full visibility of the state of backups and operation logs.
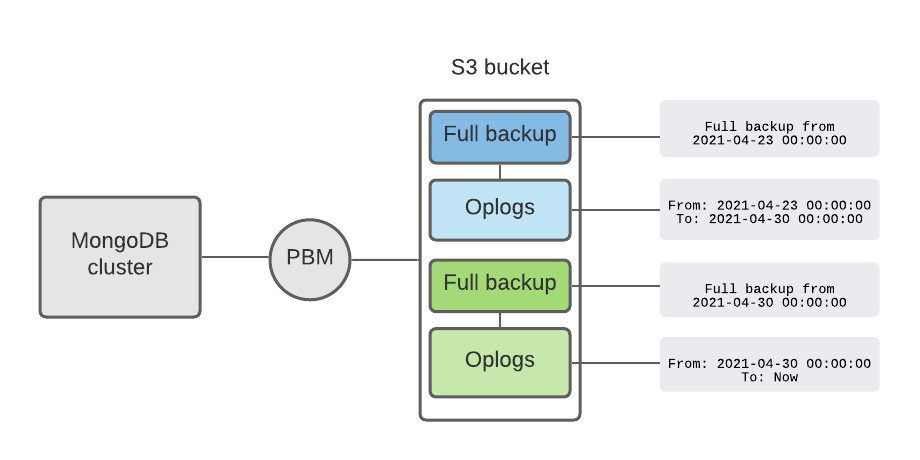
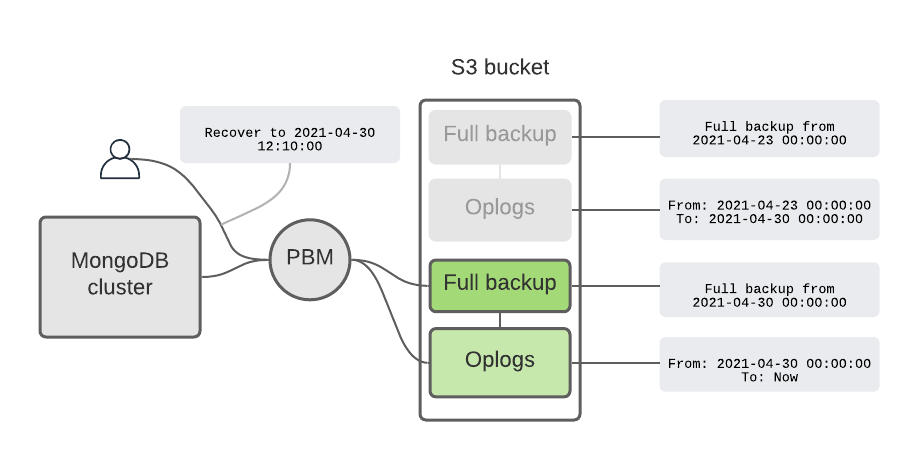
When a user wants to recover to a specific date and time, PBM figures out which full backup to use, recovers from it, and applies the oplogs.
If the user decides to use multiple S3 buckets to store backups, it means that oplogs are also scattered across these buckets. This complicates the recovery process because PBM only knows about the last S3 bucket used to store the full backup.
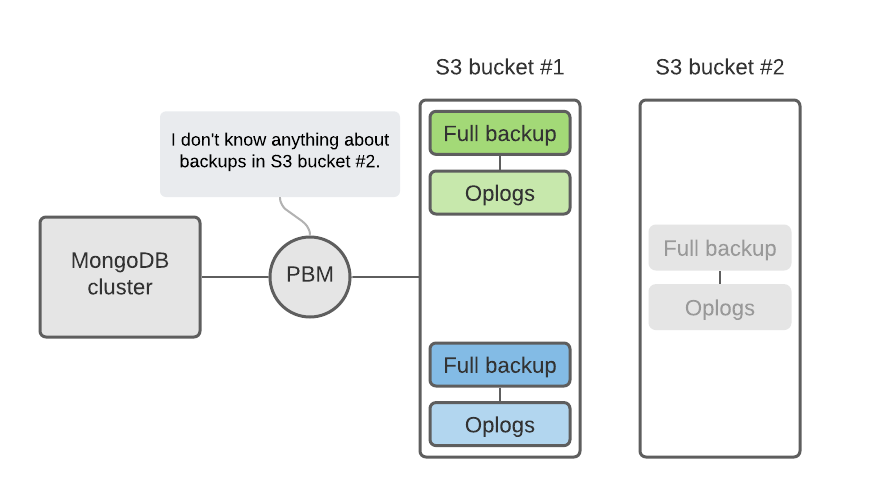
To simplify things and to avoid these split-brain situations with multiple buckets we made the following design decisions:
- Do not enable the PITR feature in the user-specified multiple buckets in
backup.storages
section. This should cover most of the cases. We throw an error if the user tries that:
"msg":"Point-in-time recovery can be enabled only if one bucket is used in spec.backup.storages"
- There are still cases where users can get into the situation with multiple buckets (ex. disable PITR and enable it again with another bucket).
- That is why to recover from the backup we request the user to specify the
backupName
(psmdb-backup
Custom Resource name) in therecover.yaml
manifest. From this CR we get the storage and PBM fetches the oplogs which follow the full backup.
- That is why to recover from the backup we request the user to specify the
The obvious question is: why can’t the Operator handle the logic and somehow store metadata from multiple buckets?
There are several answers here:
- Bucket configurations can change during a cluster’s lifecycle and keeping all this data is possible, but the data may become obsolete over time. Also, our Operator is stateless and we want to keep it that way.
- We don’t want to bring this complexity into the Operator and are assessing the feasibility of adding this functionality into PBM instead (K8SPSMDB-460).
Full Backup Needed
We mentioned before that Oplogs require full backups. Without a full backup, PBM will not start uploading oplogs and the Operator will throw the following error:
"msg":"Point-in-time recovery will work only with full backup. Please create one manually or wait for scheduled backup to be created (if configured).
There are two cases when this can happen:
- User enables PITR for the cluster
- User recovers from backup
In this release, we decided not to create the full backup automatically, but leave it to the user or backup schedule. We might introduce the flag in the following releases which would allow users to configure this behavior, but for now, we decided that current primitives are enough to automate the full backup creation.
10 Minutes RPO
Right now PBM uploads oplogs to the S3 bucket every 10 minutes. This time span is not configurable and hardcoded for now. What it means to the user is that a Recovery Point Objective (RPO) can be as much as ten minutes.
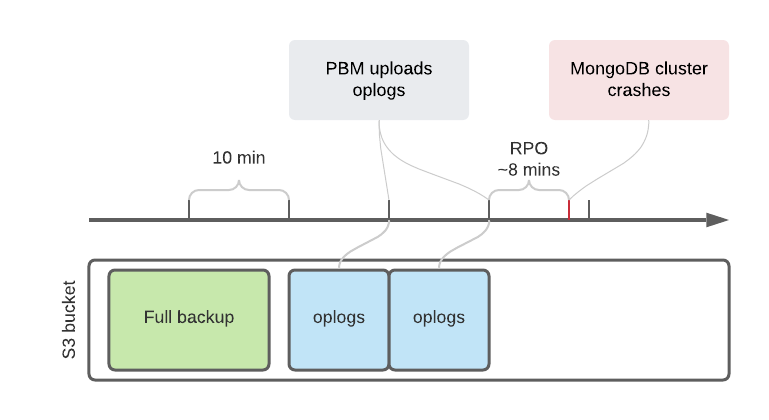
This is going to be improved in the following releases of Percona Backup for MongoDB and captured in PBM-543 JIRA issue. Once it is there, the user would be able to control the period between Oplog uploads with spec.backup.pitr.timeBetweenUploads
in cr.yaml
.
Which Backups do I Have?
So the user has Full backups and PITR enabled. PBM has a nice feature that shows all the backups and Oplog (PITR) time frames:
$ pbm list Backup snapshots: 2020-12-10T12:19:10Z [complete: 2020-12-10T12:23:50] 2020-12-14T10:44:44Z [complete: 2020-12-14T10:49:03] 2020-12-14T14:26:20Z [complete: 2020-12-14T14:34:39] 2020-12-17T16:46:59Z [complete: 2020-12-17T16:51:07] PITR <on>: 2020-12-14T14:26:40 - 2020-12-16T17:27:26 2020-12-17T16:47:20 - 2020-12-17T16:57:55
But in Operator the user can see full backup details, but cannot see the Oplog information yet without going into the backup container manually:
$ kubectl get psmdb-backup backup2 -o yaml … status: completed: "2021-05-05T19:27:36Z" destination: "2021-05-05T19:27:11Z" lastTransition: "2021-05-05T19:27:36Z" pbmName: "2021-05-05T19:27:11Z" s3: bucket: my-bucket credentialsSecret: s3-secret endpointUrl: https://storage.googleapis.com region: us-central-1
The obvious idea is to somehow store this information in psmdb-backup
Custom Resource but to do that we need to keep it updated. Updating hundreds of these objects all the time in a reconcile loop might result in pressure on the Operator and even Kubernetes API. We are still assessing different options here.
Conclusion
Point-in-time recovery is an important feature for Percona Operator for MongoDB as it reduces both RTO and RPO. The feature was present in PBM for some time already and was battle-tested in multiple production deployments. With Operator we want to reduce the manual burden to a minimum and automate day-2 operations as much as possible. Here is a quick summary of what is coming in the following releases of the Operator related to PITR:
- Reduce RPO even more with configurable Oplogs upload period (PBM-543, K8SPSMDB-388)
- Take full backup automatically if PITR is enabled (K8SPSMDB-460)
- Provide users the visibility into available Oplogs time frames (K8SPSMDB-461)
Our roadmap is available publicly here and we would be curious to learn more about your ideas. If you are willing to contribute a good starting point would be CONTRIBUTING.md in our Github repository. It has all the details about how to contribute code, submit new ideas, and report a bug. A good place to ask questions is our Community Forum, where anyone can freely share their thoughts and suggestions regarding Percona software.